
Browse Source
init
 xjc
3 years ago
xjc
3 years ago
commit
9cdb19a286
100 changed files with 136 additions and 0 deletions
+ 24
- 0
demo.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 112
- 0
parsedocx.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
test.docx
BIN
test4.docx
BIN
test4.files/image001.gif
{kind=link}

BIN
test4.files/image001.png
{kind=link}

BIN
test4.files/image002.gif
{kind=link}

BIN
test4.files/image002.png
{kind=link}

BIN
test4.files/image003.gif
{kind=link}

BIN
test4.files/image003.png
{kind=link}

BIN
test4.files/image004.gif
{kind=link}

BIN
test4.files/image004.png
{kind=link}

BIN
test4.files/image005.gif
{kind=link}

BIN
test4.files/image005.png
{kind=link}

BIN
test4.files/image006.gif
{kind=link}

BIN
test4.files/image006.png
{kind=link}

BIN
test4.files/image007.gif
{kind=link}

BIN
test4.files/image007.png
{kind=link}

BIN
test4.files/image008.gif
{kind=link}

BIN
test4.files/image008.png
{kind=link}
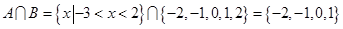
BIN
test4.files/image009.gif
{kind=link}
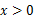
BIN
test4.files/image009.png
{kind=link}

BIN
test4.files/image010.gif
{kind=link}

BIN
test4.files/image010.png
{kind=link}
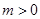
BIN
test4.files/image011.gif
{kind=link}

BIN
test4.files/image011.png
{kind=link}

BIN
test4.files/image012.gif
{kind=link}
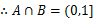
BIN
test4.files/image012.png
{kind=link}

BIN
test4.files/image013.gif
{kind=link}

BIN
test4.files/image013.png
{kind=link}

BIN
test4.files/image014.gif
{kind=link}
BIN
test4.files/image014.png
{kind=link}

BIN
test4.files/image015.gif
{kind=link}
BIN
test4.files/image015.png
{kind=link}

BIN
test4.files/image016.gif
{kind=link}

BIN
test4.files/image016.png
{kind=link}
BIN
test4.files/image017.gif
{kind=link}
BIN
test4.files/image017.png
{kind=link}

BIN
test4.files/image018.gif
{kind=link}

BIN
test4.files/image018.png
{kind=link}

BIN
test4.files/image019.gif
{kind=link}

BIN
test4.files/image019.png
{kind=link}

BIN
test4.files/image020.gif
{kind=link}

BIN
test4.files/image020.png
{kind=link}

BIN
test4.files/image021.gif
{kind=link}

BIN
test4.files/image021.png
{kind=link}
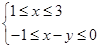
BIN
test4.files/image022.gif
{kind=link}

BIN
test4.files/image022.png
{kind=link}
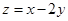
BIN
test4.files/image023.gif
{kind=link}
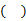
BIN
test4.files/image023.png
{kind=link}

BIN
test4.files/image024.gif
{kind=link}

BIN
test4.files/image024.png
{kind=link}

BIN
test4.files/image025.gif
{kind=link}
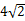
BIN
test4.files/image025.png
{kind=link}

BIN
test4.files/image026.gif
{kind=link}
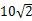
BIN
test4.files/image026.png
{kind=link}
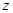
BIN
test4.files/image027.gif
{kind=link}

BIN
test4.files/image027.png
{kind=link}
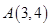
BIN
test4.files/image028.gif
{kind=link}

BIN
test4.files/image028.png
{kind=link}

BIN
test4.files/image029.gif
{kind=link}
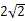
BIN
test4.files/image029.png
{kind=link}
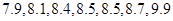
BIN
test4.files/image030.gif
{kind=link}

BIN
test4.files/image030.png
{kind=link}
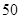
BIN
test4.files/image031.gif
{kind=link}

BIN
test4.files/image031.png
{kind=link}

BIN
test4.files/image032.gif
{kind=link}
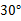
BIN
test4.files/image032.png
{kind=link}

BIN
test4.files/image033.gif
{kind=link}

BIN
test4.files/image033.png
{kind=link}

BIN
test4.files/image034.gif
{kind=link}
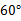
BIN
test4.files/image034.png
{kind=link}

BIN
test4.files/image035.gif
{kind=link}
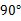
BIN
test4.files/image035.png
{kind=link}

BIN
test4.files/image036.gif
{kind=link}

BIN
test4.files/image036.png
{kind=link}

BIN
test4.files/image037.gif
{kind=link}

BIN
test4.files/image037.png
{kind=link}

BIN
test4.files/image038.gif
{kind=link}

BIN
test4.files/image038.png
{kind=link}

BIN
test4.files/image039.gif
{kind=link}

BIN
test4.files/image039.png
{kind=link}

BIN
test4.files/image040.gif
{kind=link}

BIN
test4.files/image040.png
{kind=link}

BIN
test4.files/image041.gif
{kind=link}

BIN
test4.files/image041.png
{kind=link}

BIN
test4.files/image042.gif
{kind=link}
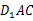
BIN
test4.files/image042.png
{kind=link}

BIN
test4.files/image043.gif
{kind=link}
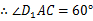
BIN
test4.files/image043.png
{kind=link}
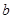
BIN
test4.files/image044.gif
{kind=link}

BIN
test4.files/image044.png
{kind=link}

BIN
test4.files/image045.gif
{kind=link}

BIN
test4.files/image045.png
{kind=link}

BIN
test4.files/image046.gif
{kind=link}

BIN
test4.files/image046.png
{kind=link}
BIN
test4.files/image047.gif
{kind=link}

BIN
test4.files/image047.png
{kind=link}
BIN
test4.files/image048.gif
{kind=link}

+ 0
- 0
test4.files/image048.png
{kind=link}
